








- 0 Comments
- 65 views
Last Active Blog
-
A-Critical
A group blog by A-critical in Atlassian Related- 6 Entries
- 3 Comments
- 6762 Views
Atlassian is great, but on occasion they let out some shady things that we should point out to keep Atlassian true to their five values: Open Company, No bullshit, Build with heart and balance, Don’t #@!% the customer, Play, as a team, Be the change you seek. When this happens, then we post about it here with the intent to make Atlassian aware of when things slip through so they can correct it.
Latest entry by 💫 Jimi Wikman,
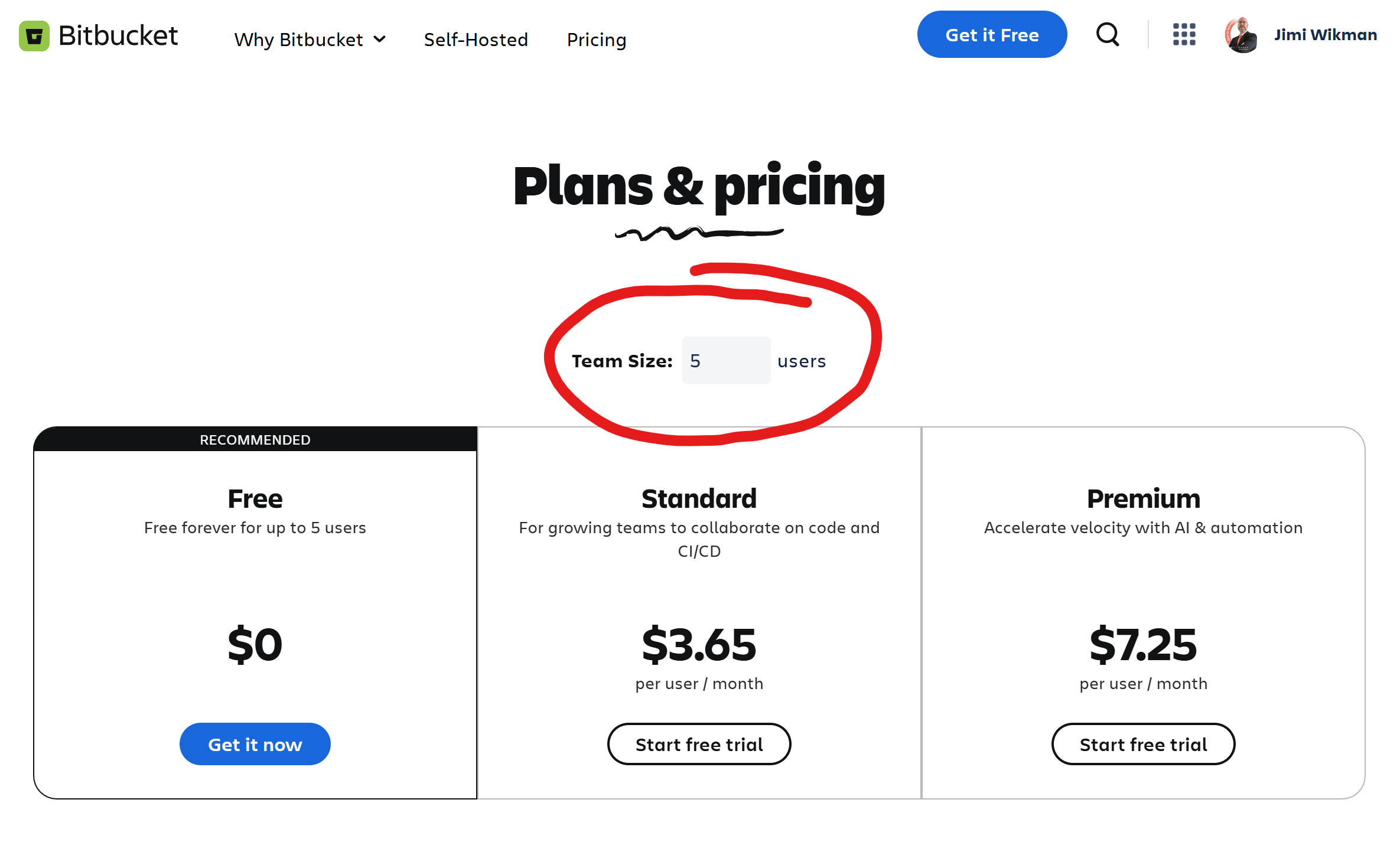
I like Bitbucket and I think that it is not a bad product at all. If you want to use Bitbucket as a single developer, or a small team of 2–3 individuals, however, it is horribly overpriced, and it is not that obvious to you as a customer! The reason is that Atlassian is using dark pattern design to trick you into thinking you will pay $3.65 for a user, but in reality you will pay $18.25 because you can't purchase fewer users than 5!
Let us take a look at what the GUI tells us when you are in Bitbucket and you go to check the plans to see if you want to upgrade.

Nowhere on this screen does it say that there is a minimum number of users that you have to pay for. This view suggests that there is no such limit at all, which is what would make sense, as there is no reason to set a limit to the number of users for a product like Bitbucket.
This is where I think you should show the expected cost for a plan change. In fact, I believe this is even mandatory, legally, in many countries as you are now not being honest about the cost, and you are basically scamming the users into paying a lot more than expected. In fact, for me, this jumped up 5 times because I just wanted the standard for myself to use on this website.
So what does the Bitbucket pricing page say?

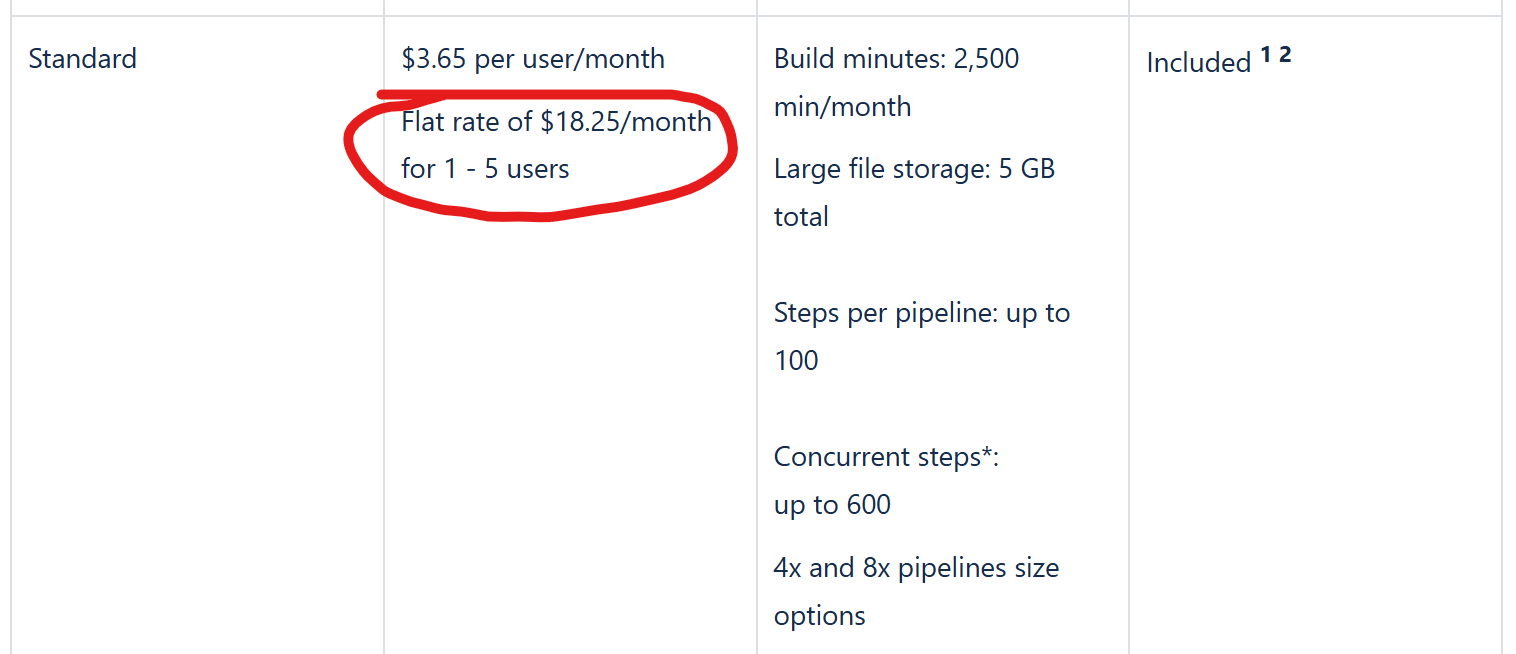
Again this says $3.65 per user per month and nowhere can you find the information that there is a minimum number of 5 users that you have to pay for. They have purposely added 5 users to the pricing table, which technically makes this value true, as it is $3.65 per user if you select 5 users. For a total of $18.25, even for just one user.
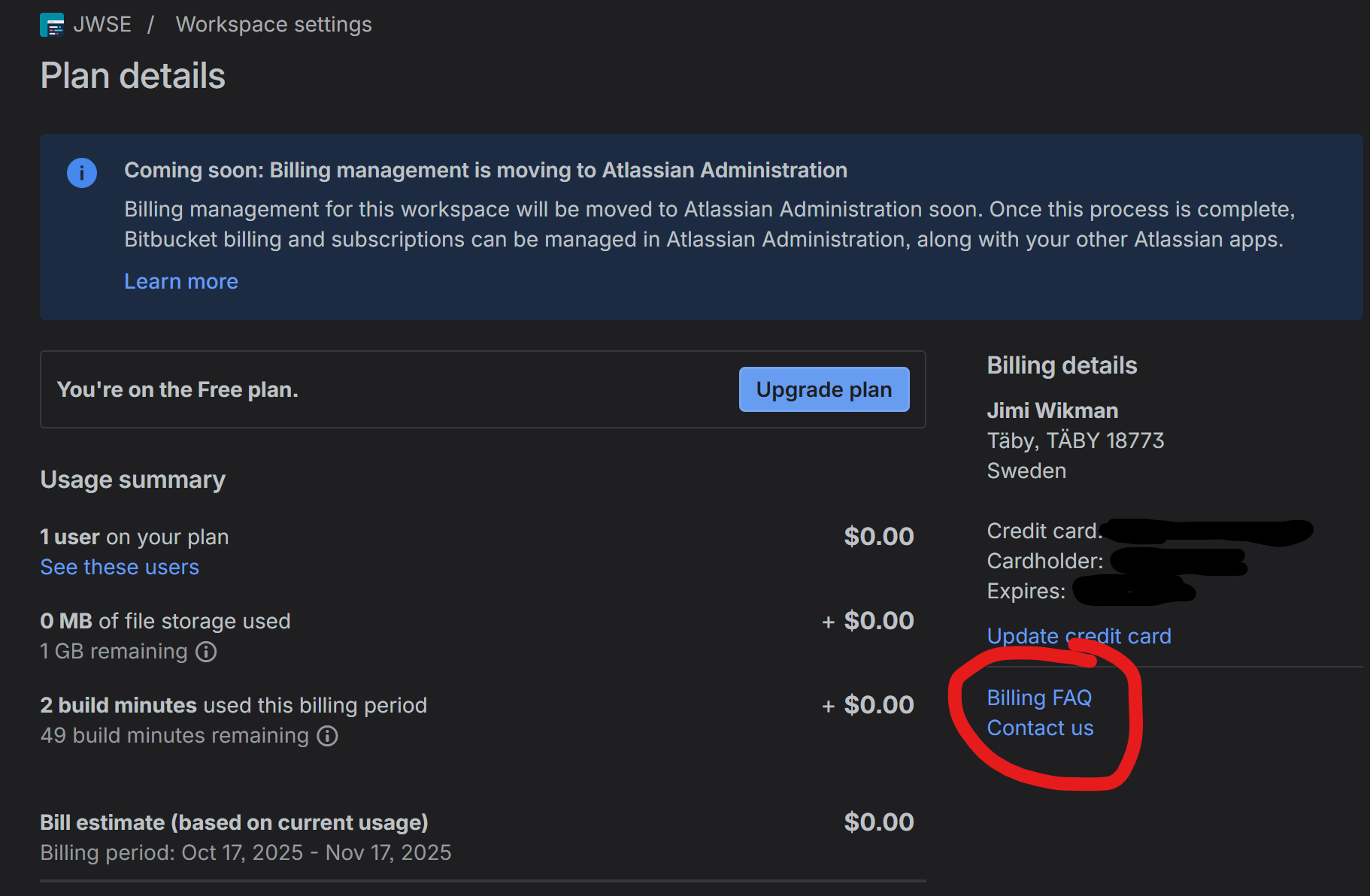
The ONLY place I have found where the actual pricing and the requirement that you have to pay for a minimum of 5 users are found is on the pricing FAQ, which is a tiny side link in Bitbucket in the overview page:

This tiny link is also available on the Bitbucket pricing page in the FAQ, but not under a section you would expect, but under the section on over usage:

On that page that you can find if you are really, really, really looking for it and explore all links, then you will find the following information:

This kind of practices to hide costs in the hopes that someone will miss that the monthly cost is many times higher is just a bad look for Atlassian. For me as an Atlassian fan who happen to love the functionality of Bitbucket and Bitbucket pipelines, this is a huge turn-off. Not just that I have to pay almost as much to use Bitbucket standard than I do for Jira premium, which is priced at $18.30 per user and month, but the fact that they are using omitting that on the pricing pages by using dark pattern design to trick us...
I will use the free version, as there is zero reason for me to pay that much for the standard functionality. This will also 100% prevent me from getting the software collection unless they will have a pricing that will work for me as a single user, or a team smaller than 5.
I am disappointed to say the least.
Recent Entries
Blogs

- 0 Comments
- 386 views

- 6 Comments
- 2,024 views

- 0 Comments
- 972 views
.webp.8358d6da7ebe557cde3c0cf9f121ba8e.webp)
- 0 Comments
- 1,098 views
- 0 Comments
- 67 views

- 0 Comments
- 52 views

- 0 Comments
- 1,877 views
.webp.65e3ff032b3e56af668fd62cbf24d6bd.webp)
- 3 Comments
- 2,687 views

- 0 Comments
- 5,169 views

- 0 Comments
- 1,924 views

- 0 Comments
- 1,376 views

- 0 Comments
- 1,356 views
Blogs
-
A-Critical
A group blog by A-critical in Atlassian Related- 6 Entries
- 3 Comments
- 6762 Views
Atlassian is great, but on occasion they let out some shady things that we should point out to keep Atlassian true to their five values: Open Company, No bullshit, Build with heart and balance, Don’t #@!% the customer, Play, as a team, Be the change you seek. When this happens, then we post about it here with the intent to make Atlassian aware of when things slip through so they can correct it.
Latest entry by 💫 Jimi Wikman,
I like Bitbucket and I think that it is not a bad product at all. If you want to use Bitbucket as a single developer, or a small team of 2–3 individuals, however, it is horribly overpriced, and it is not that obvious to you as a customer! The reason is that Atlassian is using dark pattern design to trick you into thinking you will pay $3.65 for a user, but in reality you will pay $18.25 because you can't purchase fewer users than 5!
Let us take a look at what the GUI tells us when you are in Bitbucket and you go to check the plans to see if you want to upgrade.
Nowhere on this screen does it say that there is a minimum number of users that you have to pay for. This view suggests that there is no such limit at all, which is what would make sense, as there is no reason to set a limit to the number of users for a product like Bitbucket.
This is where I think you should show the expected cost for a plan change. In fact, I believe this is even mandatory, legally, in many countries as you are now not being honest about the cost, and you are basically scamming the users into paying a lot more than expected. In fact, for me, this jumped up 5 times because I just wanted the standard for myself to use on this website.
So what does the Bitbucket pricing page say?
Again this says $3.65 per user per month and nowhere can you find the information that there is a minimum number of 5 users that you have to pay for. They have purposely added 5 users to the pricing table, which technically makes this value true, as it is $3.65 per user if you select 5 users. For a total of $18.25, even for just one user.
The ONLY place I have found where the actual pricing and the requirement that you have to pay for a minimum of 5 users are found is on the pricing FAQ, which is a tiny side link in Bitbucket in the overview page:
This tiny link is also available on the Bitbucket pricing page in the FAQ, but not under a section you would expect, but under the section on over usage:
On that page that you can find if you are really, really, really looking for it and explore all links, then you will find the following information:
This kind of practices to hide costs in the hopes that someone will miss that the monthly cost is many times higher is just a bad look for Atlassian. For me as an Atlassian fan who happen to love the functionality of Bitbucket and Bitbucket pipelines, this is a huge turn-off. Not just that I have to pay almost as much to use Bitbucket standard than I do for Jira premium, which is priced at $18.30 per user and month, but the fact that they are using omitting that on the pricing pages by using dark pattern design to trick us...
I will use the free version, as there is zero reason for me to pay that much for the standard functionality. This will also 100% prevent me from getting the software collection unless they will have a pricing that will work for me as a single user, or a team smaller than 5.
I am disappointed to say the least.
Recent Entries
-
Atlassian News
A blog by 💫 Jimi Wikman in Atlassian Related- 4 Entries
- 6 Comments
- 2927 Views
Atlassian publish news all the time, but it is not easy to stay on top with all the things that are happening. In this blog we will post things that we think are of importance for you as an Atlassian user, an Atlassian consultant or as an Atlassian administrator.
Latest entry by 💫 Jimi Wikman,
It was a difficult Monday morning for Atlassian today as almost all their services got affected by a DNS problem for the DynamoDB API endpoint in US-EAST-1 cluster at AWS. This incident did not just affect Atlassian of course, but had several other sites and services feel the effect of this incident as well. The AWS team quickly identified the root cause and has been working hard to resolve this during the day. As of right now, it seems that most of the services has recovered, but API errors are still causing problems.
While this has been cause for some issues where I personally was unable to access certain customers admin sections and some automations were not running, overall the impact has not been very great for me today. I did however get a bit annoyed when I could not access the old API documentation for Confluence data center when the newer seemed to work fine, but an event that was not too bad and lasted an hour or so before it was resolved.
It can't be a great day for Atlassian support today to deal with this incident that is not due to anything they can actually control. It does however raise the question of redundancies and how outages like this can actually happen. As reported by Peter Sayer over at Networkworld, who reported this early on, this is not the first big outage that has happened recently:
A few months ago, it was Microsoft with egg on its face, as a problem in Azure’s US East region rippled out to affect other organizations. Before that, a series of outages at IBM Cloud had customers wondering if they had made the right design choices. The third, shorter, outage affected 54 IBM Cloud services.
AWS Incident Log:
https://health.aws.amazon.com/health/status
Increased Error Rates and Latencies
Oct 20 10:03 AM PDT We continue to apply mitigation steps for network load balancer health and recovering connectivity for most AWS services. Lambda is experiencing function invocation errors because an internal subsystem was impacted by the network load balancer health checks. We are taking steps to recover this internal Lambda system. For EC2 launch instance failures, we are in the process of validating a fix and will deploy to the first AZ as soon as we have confidence we can do so safely. We will provide an update by 10:45 AM PDT.
Oct 20 9:13 AM PDT We have taken additional mitigation steps to aid the recovery of the underlying internal subsystem responsible for monitoring the health of our network load balancers and are now seeing connectivity and API recovery for AWS services. We have also identified and are applying next steps to mitigate throttling of new EC2 instance launches. We will provide an update by 10:00 AM PDT.
Oct 20 8:43 AM PDT We have narrowed down the source of the network connectivity issues that impacted AWS Services. The root cause is an underlying internal subsystem responsible for monitoring the health of our network load balancers. We are throttling requests for new EC2 instance launches to aid recovery and actively working on mitigations.
Oct 20 8:04 AM PDT We continue to investigate the root cause for the network connectivity issues that are impacting AWS services such as DynamoDB, SQS, and Amazon Connect in the US-EAST-1 Region. We have identified that the issue originated from within the EC2 internal network. We continue to investigate and identify mitigations.
Oct 20 7:29 AM PDT We have confirmed multiple AWS services experienced network connectivity issues in the US-EAST-1 Region. We are seeing early signs of recovery for the connectivity issues and are continuing to investigate the root cause.
Oct 20 7:14 AM PDT We can confirm significant API errors and connectivity issues across multiple services in the US-EAST-1 Region. We are investigating and will provide further update in 30 minutes or soon if we have additional information.
Oct 20 6:42 AM PDT We have applied multiple mitigations across multiple Availability Zones (AZs) in US-EAST-1 and are still experiencing elevated errors for new EC2 instance launches. We are rate limiting new instance launches to aid recovery. We will provide an update at 7:30 AM PDT or sooner if we have additional information.
Oct 20 5:48 AM PDT We are making progress on resolving the issue with new EC2 instance launches in the US-EAST-1 Region and are now able to successfully launch new instances in some Availability Zones. We are applying similar mitigations to the remaining impacted Availability Zones to restore new instance launches. As we continue to make progress, customers will see an increasing number of successful new EC2 launches. We continue to recommend that customers launch new EC2 Instance launches that are not targeted to a specific Availability Zone (AZ) so that EC2 has flexibility in selecting the appropriate AZ. We also wanted to share that we are continuing to successfully process the backlog of events for both EventBridge and Cloudtrail. New events published to these services are being delivered normally and are not experiencing elevated delivery latencies. We will provide an update by 6:30 AM PDT or sooner if we have additional information to share.
Oct 20 5:10 AM PDT We confirm that we have now recovered processing of SQS queues via Lambda Event Source Mappings. We are now working through processing the backlog of SQS messages in Lambda queues.
Oct 20 4:48 AM PDT We continue to work to fully restore new EC2 launches in US-EAST-1. We recommend EC2 Instance launches that are not targeted to a specific Availability Zone (AZ) so that EC2 has flexibility in selecting the appropriate AZ. The impairment in new EC2 launches also affects services such as RDS, ECS, and Glue. We also recommend that Auto Scaling Groups are configured to use multiple AZs so that Auto Scaling can manage EC2 instance launches automatically. We are pursuing further mitigation steps to recover Lambda’s polling delays for Event Source Mappings for SQS. AWS features that depend on Lambda’s SQS polling capabilities such as Organization policy updates are also experiencing elevated processing times. We will provide an update by 5:30 AM PDT.
Oct 20 4:08 AM PDT We are continuing to work towards full recovery for EC2 launch errors, which may manifest as an Insufficient Capacity Error. Additionally, we continue to work toward mitigation for elevated polling delays for Lambda, specifically for Lambda Event Source Mappings for SQS. We will provide an update by 5:00 AM PDT.
Oct 20 3:35 AM PDT The underlying DNS issue has been fully mitigated, and most AWS Service operations are succeeding normally now. Some requests may be throttled while we work toward full resolution. Additionally, some services are continuing to work through a backlog of events such as Cloudtrail and Lambda. While most operations are recovered, requests to launch new EC2 instances (or services that launch EC2 instances such as ECS) in the US-EAST-1 Region are still experiencing increased error rates. We continue to work toward full resolution. If you are still experiencing an issue resolving the DynamoDB service endpoints in US-EAST-1, we recommend flushing your DNS caches. We will provide an update by 4:15 AM, or sooner if we have additional information to share.
Oct 20 3:03 AM PDT We continue to observe recovery across most of the affected AWS Services. We can confirm global services and features that rely on US-EAST-1 have also recovered. We continue to work towards full resolution and will provide updates as we have more information to share.
Oct 20 2:27 AM PDT We are seeing significant signs of recovery. Most requests should now be succeeding. We continue to work through a backlog of queued requests. We will continue to provide additional information.
Oct 20 2:22 AM PDT We have applied initial mitigations and we are observing early signs of recovery for some impacted AWS Services. During this time, requests may continue to fail as we work toward full resolution. We recommend customers retry failed requests. While requests begin succeeding, there may be additional latency and some services will have a backlog of work to work through, which may take additional time to fully process. We will continue to provide updates as we have more information to share, or by 3:15 AM.
Oct 20 2:01 AM PDT We have identified a potential root cause for error rates for the DynamoDB APIs in the US-EAST-1 Region. Based on our investigation, the issue appears to be related to DNS resolution of the DynamoDB API endpoint in US-EAST-1. We are working on multiple parallel paths to accelerate recovery. This issue also affects other AWS Services in the US-EAST-1 Region. Global services or features that rely on US-EAST-1 endpoints such as IAM updates and DynamoDB Global tables may also be experiencing issues. During this time, customers may be unable to create or update Support Cases. We recommend customers continue to retry any failed requests. We will continue to provide updates as we have more information to share, or by 2:45 AM.
Oct 20 1:26 AM PDT We can confirm significant error rates for requests made to the DynamoDB endpoint in the US-EAST-1 Region. This issue also affects other AWS Services in the US-EAST-1 Region as well. During this time, customers may be unable to create or update Support Cases. Engineers were immediately engaged and are actively working on both mitigating the issue, and fully understanding the root cause. We will continue to provide updates as we have more information to share, or by 2:00 AM.
Oct 20 12:51 AM PDT We can confirm increased error rates and latencies for multiple AWS Services in the US-EAST-1 Region. This issue may also be affecting Case Creation through the AWS Support Center or the Support API. We are actively engaged and working to both mitigate the issue and understand root cause. We will provide an update in 45 minutes, or sooner if we have additional information to share.
Oct 20 12:11 AM PDT We are investigating increased error rates and latencies for multiple AWS services in the US-EAST-1 Region. We will provide another update in the next 30-45 minutes.
Recent Entries
-
The Advanced Atlassian Administration Guidebook News
A blog by 💫 Jimi Wikman in Atlassian Related- 2 Entries
- 0 Comments
- 320 Views
This is a blog where I post updates and news regarding my book, The Advanced Atlassian Administration Guidebook.
Latest entry by 💫 Jimi Wikman,
This week I have been a bit preoccupied with finding a new job. I have had 4 interviews this week and this weekend I have been wrestling with a decision as I have 3 very good work opportunities to choose from. Despite this I have been putting in some work on my book and I have added a fair bit of text in the Governance, Authority and Strategy chapters. I have also made some updates in other areas to clear some things up and revise things.
In the Authority section I added information about leadership with the goal to define 8 leadership styles and how to use them in your role as Atlassian administrator. I know not a lot of Atlassian administrators think about leadership as they are often in a servant position, but I want to make it clear that you need to take lead when you have ownership over a work tool that very often is business critical.
This then bled over to the Strategy section where I added information on organization maturity with some paragraphs about the user adoption process and the user adoption curve. I also started to add information on how to define product and platform criticality using the application criteria and criticality scale. While this is a fairly small part, it is important to be able to do this and show it to management in case you need to show how business critical the Atlassian platform is in an organization. It is also important so you can direct your strategies to the actual criticality so you don't act too lose or too strict in relation to it.
In the Governance I have started to add sections for how to work if your organization have governance and if it does not have. This is mostly for when you don't have it, which is the norm I think, as that can be really tricky and easily burn you out.
The last page is now page 98, but there are some half pages and whole pages still in that mix. Still there is progress, and I am not feeling any writer's block. It is just the process of getting a new job that is taking up most of my attention at the moment, but that should change soon.
Recent Entries
-
Latest entry by 💫 Jimi Wikman,
Working on multiple projects at the same time is sadly a common experience for many of us working in IT. Many split their attention on at least 2 projects or responsibility areas. This comes at a cost however, not just for the person splitting their time, but also for the people they work with.
Few lift an eyebrow at the mention that someone is in a project for as low as 20% these days. Sadly no one really bat an eyelash when a coworker break down mentally and get sick from the mental stress either. In my line of work as an IT consultant I often see people splitting their time and I see what it cost those persons as well as the projects they are doing their best to contribute to.
Not to long ago I witnessed a co-worker taking a seat after lunch looking pale. A faded smile and assurance that he would join soon and just needed a moment to himself was followed by an ambulance taking him to the hospital. It took him a year to come back to work. More than once have I seen people pass out in a meeting and outbursts of anger and frustration for small things happen on a regular basis by even the most gentle and kind persons.
What could possibly cause such extreme amounts of stress? The answer is that all of these people have suffered from extreme forms of content switching. As a human we need time to focus in order to make rational decisions. As the time to focus is interrupted we experience content switching. That is that moment when you are forced to go from one focused thought to another. This change of focus comes at a cost of mental energy and eveyone need a different amount of time to make the switch mentally.
As a manager you do this a lot as part of your work. That mental flexibility and speed that you have as a manager serve you well to manage most situations. That is because the content switching is still within one context. When you need to split your attention on multiple context however the cost will increase exponentially and with time, you will build up negative stress. If you do not reduce that stress it will eventually cause physical harm and you will hit that famous wall head first.
Other fields in IT have the same situation, but there is one group that suffer from this more than any other group: the developers. Developers unlike most other groups are focused oriented, mening that they spend more time in their own minds setting up structures and logical flows that create the code they write. Once interrupted it takes far longer to get back to their focused state of mind. Fortunately developers are less likely to work on multiple projects at the same time, but when they do the damage is more severe than for other groups. Designers have a similar situation, but have an easier time to make the mental switch.
How to mitigate and avoid getting burned out
Speed is everything, or so they make you think. Meeting after meeting where you jump from onte topic to the next in frantic speed. As you solve issue after issue with your quick and skilled mind you will experience a sense of accomplishment. This is because your brain reward you for it and it becomes an addiction. Soon you will crave it and like a junkie you will crave your fix even when you are off work. Eventually the rewards will not measure up with the cost and you will get frustrated and eventually have problem being happy. A sense of feeling empty and caught in a endless loop is your last warning before you bend the knee to the mental exhaustion and collapse.
The price you pay fror strecthing yourself thin benefit no one as you break down. There are things you can do however to prevent this. Both as regular practices, but also as strategies and rules you set for yourself.
Managers, Requirements & Business people
-
Make time for focused work - As a manager or if you work in the Business area the biggest danger is having long periods without proper focus. Meetings and workshops take up much of your time, so make sure you dedicate at least 1 hour every day for focused work (no, not during lunch...). This is a time where you take time to be fully alone without distractions to focus on emails, power points and whatever else you have promised to do. This will naturally lower your stress levels and allow you a form of soft reboot. If this does not work, then dedicate a longer period 1-2 days a week. This can be that you work from home one day once a week or two half days for example.
-
Turn off at the end of the day - The most common mistake managers do is that they never stop working. My suggestion is that you leave the computer at work if you can, or leave it in the bag when you get home. The same goes for the phone. make sure it is turned off as soon as you leave work, or at least as soon as you get home. If you are required to be reached every hour of they day, then you are constantly on stand by and never relaxed. Not only is this bad for your health, it is actually a legal issue as well in many countries as you are working over time. Stop doing that today!
-
Say no or delegate - If you get asked to split your attention between multiple areas or you feel that thet area you are in charge of is becoming difficult to manage within your normal working hours, then you should say no or delegate. Saying no is always difficult since most managers are driven by status or to help others. It s however a very useful skill to master and it will save you a lot of stress. Just make sure you say no for the right reason and not to avoid stepping out of your comfort zone, because that is actually a good thing.
This is very hard in some cultures and if you feel that this is impossible, then find a way within the situation you find yourself. A trick that you can try is to promote people that work for you or offer to teach someone what you do. Just make sure you make sure the person you delegate to also have their regular workload reduced or you will burn them out instead.
- Never try to lead someone that is not fully commited - Having people in your team that split their time is a cause for much frustration. No matter how much time they dedicate to your project you will never get that time because of the cost of content switching. You will also find the moments when they are not working on your project, no matter how rare they are, to be annoying and inconvenient. My advice is to never try to lead anyone who is not fully commited to your project because of this.
Developers & Designers
-
Never split your work - There are times when you might be asked to split your work and my advice to you is to say no. No matter what split you have you will never be able to dedicate 100% time between the two. Each split will cost you a lot of time just for switching between them and the mental toll will be far worse then you think. If you split yourself 50/50 you will do 40% in each project and you will work 120%. You will constantly feel stressed and that you do not do the work you are supposed to. It will eventually break you down mentally so never accept a split work situation.
-
Avoid meetings if you can - Some meetings you need to attend, but try to avoid meetings that are not necessary. The reason is that a meeting, even if it is just 30 minutes long, will completely content switch you from your work. Unlike a short interruption that cost around 10-15 minutes of lost time a meeting will cost at least double that. Some meetings may be even more disruptive causing fragmentaion of thought for hours afterwards as you try to focus on work, but have the new information or task in mind as well.
-
Take time to clarify things - The biggest issue for most developers and designers is unclear requirements and unclear expectations. If you take time to clarify things, then you will save a lot of time. That is because not only will you wate time trying to find answers, you also suffer from content switching. This can make a simple question cost hours of focused work. Everyone have different need when it comes to clarity so do not rush sprint startups, requirement sessions or technical architect forums. Make sure everyone in the team understand what to do and why. This way you can focus on working without having to find answers or explain things to other members of your team.
- Agree on work environments - All teams have different compositions. Some need a lot fo focus, others less. Make sure you define wht your team needs and agree on how you will work. I have had teams that work with the hand so they just put up the hand to let you know they are busy. This way you can signal that the person have to come back later as you are deep into something right now. If that is still to disruptive then use a hat or something that indicate this before you even approach teh developer. In some cases it can be a good idea to assign a team lead or project manager to handle all outside requests to further reduce disruptions. Whatever your team need, make sure it is defined and agreed upon by everyone.
Test
-
Insert yourself into the information flow - As testers it is sometimes difficult to know what is going on. This is because testers can be seen as an external part of the development flow. This usually means test comes in long after requirements and development planning, which is not only stupid from a quality perspective, it is also cause for frustration and stress. As testers you should sign off on all requirements and you need to be on top of development and deploys. So if you are not included in the information flows you need to be in, then make sure that you are. This way you do not need to run around looking for information or work within an isolated workflow. If you do not, then you will constantly feel stressed and frustrated.
-
Agree on bug flow with developers - As testers you should not sit and verify browser compability or standard flows. These should already be well tested by the developers. If this is not the case then you will feel that you are just writing bugs all days and no development ever get past test. This is a bad situation and you should make sure there is a proper definition of done that prevent this.
When you find a bug you often want to discuss this with a developer. Doing so is disruptive however and I suggest that you set aside two slots every day where you can go over the defects with the team when it does the least damage. This can be done directly after the daily standup and directly after lunch as that is also when many teams collaborate on code reviews and so on. Just agree with the developers when and how you will go over the defects to ensure the impact is as small as possible.
These are just a few small tips on how to reduce stress and what the cost is for stretching yourself thin by splitting your attention between multiple projects. Most of these may be most relevant to a certain group, but most of them are valid for all groups. Content switching and bad work processes cost billions every day and they cause health issues that should not be underestimated.
Stress related illness is increasing and in many fields you can name at least one or two persons that you work with that have suffered from being burned out. In Japan there is even a specific word for working yourself to death: Karoshi. So be wary of the many ways that you can harm yourself unintentionally. One good start to protect yourself is to never accept working on multiple projects at the same time.
If you have more tips, please share to help others avoid getting burned out.
-
Make time for focused work - As a manager or if you work in the Business area the biggest danger is having long periods without proper focus. Meetings and workshops take up much of your time, so make sure you dedicate at least 1 hour every day for focused work (no, not during lunch...). This is a time where you take time to be fully alone without distractions to focus on emails, power points and whatever else you have promised to do. This will naturally lower your stress levels and allow you a form of soft reboot. If this does not work, then dedicate a longer period 1-2 days a week. This can be that you work from home one day once a week or two half days for example.
(1).jpg.72651b3ee7d06f35474e1e83624356b8.jpg)

